遺伝情報解析の進化に伴いヒトゲノムの全配列解読が可能となった今、遺伝情報を統計的に解析する遺伝統計学と呼ばれる、新しい分野が注目されている。ゲノムは“現在”における個々の健康や疾病、嗜好、行動様式などあらゆる遺伝的関わりを記録するが、ゲノムを統計的に読み解くことで“過去”にどのような進化が影響したのかが分かってくるという。遺伝統計学は疾病リスクを予測し、個々の健康をはじめ公衆衛生など社会に大きく貢献していくはずだ。

イラストレーション/北澤平祐
遺伝情報解析の進化に伴いヒトゲノムの全配列解読が可能となった今、遺伝情報を統計的に解析する遺伝統計学と呼ばれる、新しい分野が注目されている。ゲノムは“現在”における個々の健康や疾病、嗜好、行動様式などあらゆる遺伝的関わりを記録するが、ゲノムを統計的に読み解くことで“過去”にどのような進化が影響したのかが分かってくるという。遺伝統計学は疾病リスクを予測し、個々の健康をはじめ公衆衛生など社会に大きく貢献していくはずだ。

東京大学大学院医学系研究科分子細胞生物学専攻生化学・分子生物学講座教授
2005年、東京大学医学部医学科卒業。2011年、同大大学院医学系研究科内科学専攻博士課程修了。博士(医学)取得。大阪大学大学院医学系研究科遺伝統計学教授。理化学研究所生命医科学研究センターシステム遺伝学チーム チームディレクター兼任。2022年から現職。
将来どんな疾患リスクを抱えやすいのか。食べ物の嗜好はどのように決まるのか。そして、人はどのようにして結婚相手を選んでいるのか——。
これら人間の行動や選択の背後にあるゲノム情報を統計解析によって読み解き、個人と集団の健康、行動、そして社会構造までも見つめ直す。それが「遺伝統計学」という新しい学問分野である。
この分野で世界的に注目を集める研究を推進しているのが、東京大学大学院医学系研究科・岡田随象教授だ。
岡田教授はもともと医師を志し、医学部卒業後に初期臨床研修を2年間経験した。しかし、臨床の現場での長時間労働の厳しさに直面し、自らの道を見直すことになる。
「僕は徹夜があまり得意ではなかったんです。当時の臨床の現場では、36時間ぶっ続けで働くのが当たり前のような時代でしたから、自分にはとても無理だと実感しました」
社会医学や保健医学に関心を持ち、医学部生のときにはタイやキューバに研修に行ったりしつつ、自分の道を模索していた。そして、臨床研修の合間にたまたま読んだ論文で触れられていたゲノムの世界が、岡田教授の好奇心を揺さぶった。
「ヒトゲノムの全配列がまだ解明されていなかった時代。医学部の授業ではまだ解読が完了していない前提で学んでいたのに、一方で世界では、国際HapMap計画(ヒト集団のゲノム配列の多様性から病気や薬に対する反応性に関わる遺伝子変異を発見するために基盤整備を行う国際プロジェクト)などすでにゲノム配列の個人差を前提に研究が進みつつありました。個々の遺伝子ではなく、ゲノム全体を俯瞰して病気や特徴を捉える時代が来ると思い、わくわくしました」
当時は、日本にはヒト集団のゲノムデータを統計学で解析できる人材がほとんどいなかった。それならば自分がやってみようと岡田教授は考え、東京大学医科学研究所の山田亮准教授(当時)のところに学びに行くようになった。
「こういった、データを相手にする研究なら実験時間に縛られず、徹夜もしなくて済みそうだな、という現実的な理由もありました(笑)」
当時、疾患に関連する遺伝子は「もう見つからない」といわれていた。しかし、ちょうどその頃、遺伝統計学の手法として「ゲノムワイド関連解析(GWAS)」が登場し、それまでの常識が覆される。これは数百万カ所の遺伝子変異(一塩基多型:SNP)と疾患や形質との関連を統計的に導き出す方法で、従来見つけられなかった“ありふれた病気”のリスク遺伝子を明らかにすることが可能になった。
岡田教授は大学院生時代から、東京大学医科学研究所の中村祐輔教授(当時)率いる「バイオバンク・ジャパン(BBJ)」に参加する。BBJは日本人約27万人のゲノムデータを収集した大規模バイオバンクである。BBJデータベースの解析を通じて、200以上の疾患や表現型に対して関連遺伝子を特定する成果を上げ、世界的にも高く評価されている。
疾患ゲノム研究が一段落した頃、岡田教授は新たなテーマに着手する。「ヒトはどのように進化してきたか」を知るために、ゲノムを用いて進化の足跡をたどる研究である。最初に取り組んだのは、自然選択圧——つまり進化の過程で特定の遺伝子変異が有利・不利とされる環境的圧力——の解析だった。
「現代人のゲノムは“現在”を記録していますが、遺伝統計学で読み解けば、“過去”にどういう進化の圧力が働いていたかも見えてくるんです。例えば、マラリアが蔓延する地域では、鎌状赤血球症の遺伝子変異が広まりました。それは、マラリアへの耐性を得るという進化的な利益があったからです」
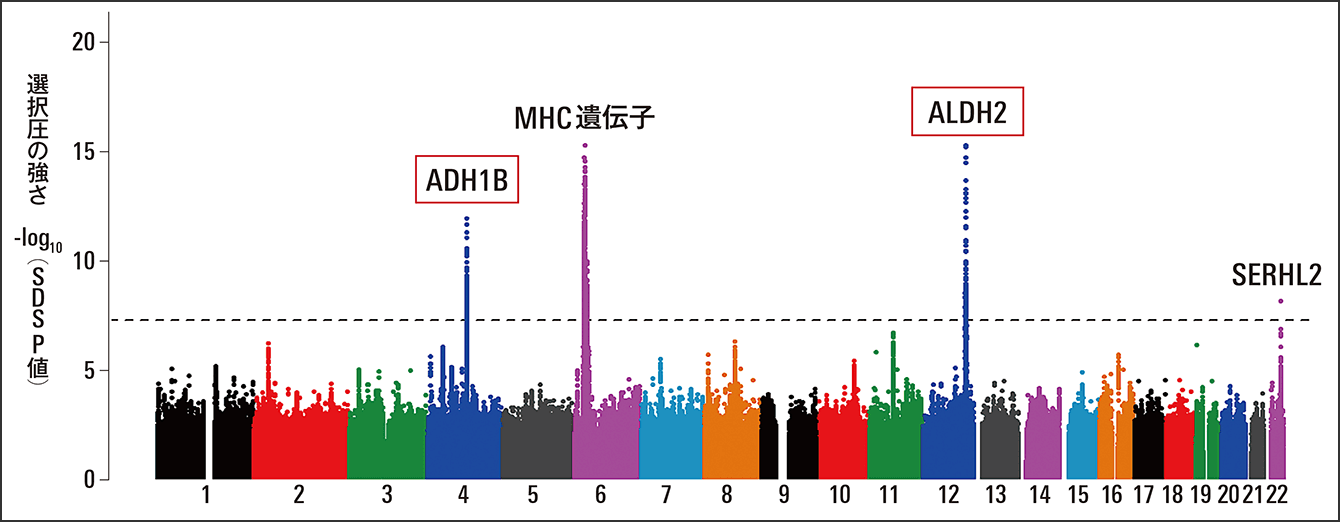
岡田教授は、日本人集団2200人の高深度全ゲノムシークエンス解析を実施し、日本列島で過去数千年間にどのようなゲノムの変化があったのかを明らかにした(図1)。特に興味深かったのは、「お酒に弱い体質」が進化的に選ばれてきたという発見だった。
 Okada Y, et al.
Okada Y, et al.図1 日本人集団における過去数千年間の選択圧日本人2200人の高深度全ゲノムシークエンス解析を実施したところ、アルコール代謝に関係するADH1BやALDH2という遺伝子の変異が過去数千年で急速に高まっていたことが分かった。
「アルコール代謝に関係するADH1BやALDH2という遺伝子に変異があると、アルデヒドの分解が遅くなり、お酒に弱くなる。面白いことに、これらの変異の頻度は、過去数千年で日本人集団において急速に高まっていたんです」
なぜ、人類はあえて“お酒に弱くなる”方向に進化したのか。その理由はまだ明らかではないが、主に東アジアの稲作地域で急速にその変異が広がっていた。そのため水田での作業により寄生虫感染のリスクが高まる環境下で、アルデヒド濃度の高い体質が何らかの防御的効果を持っていた可能性があるという仮説もある。
一方、“お酒に弱くなる”遺伝子変異は日本だけでなく、世界各地で増加傾向にあることから、「人類全体として“お酒に弱く進化している”のかもしれない」と岡田教授は語る。
「酒は百薬の長と呼ばれた時代は変わっていくかもしれません」
このような遺伝子と嗜好の関係は、「食」にも及ぶ。例えば、お酒に弱くなるALDH2の遺伝子変異を持つ人は、コーヒーやヨーグルトを好む傾向があるという。
「つまり、“何を食べるか”という選択も、部分的には遺伝的に規定されているのです」
こうした遺伝的傾向は、腸内細菌叢(マイクロバイオーム)にも影響を及ぼす。大阪大学で収集されたデータを用いた腸内細菌叢解析では、日本は他国に比べて納豆菌の定着率が高く、日本人特有の食文化と共進化してきた可能性が示唆された。「ゲノム→食の嗜好→腸内細菌→健康リスク」という連鎖構造が浮かび上がってきたのである。
さらに、誰と結婚するか——という人生の選択も、実は遺伝的傾向とまったくの無関係ではない。岡田教授が注目するのは「同類交配」と呼ばれる現象で、例えば身長や学歴など、似た特徴を持つ者同士が結婚する傾向があるというものだ。
「遺伝学は、結婚相手をランダムに集団中で選ぶという前提で研究が行われていますが、お見合いサービスは世界中の文化でありますし、昔から人間は結婚相手をランダムには選んでいないんです。だから同類交配という、似たもの同士で子を残す確率が“偶然”より高くなる現象が、以前から指摘されています。これには実は集団としてのメリットもあって、みんながランダムに結婚すると、子どもの表現型はどんどん平均に近づき、結果として集団中の表現型の多様性が減ってしまいます。例えば、欧米人集団では身長が高い人同士で結婚する傾向が見られますが、そうすることで、結果として背の高い人が集団中に維持されてきたわけです」
これまでは表現型のデータ解析に基づき同類交配が調べられてきたが、ゲノムの観点からも解析が可能になってきているという。遺伝学的に同類交配を調べると、1つ前の世代の人たちがどういう表現型同士で結婚した傾向があったのか、間接的に推定できるのだという。
「ゲノムを調べると、やはり欧米人集団は身長や学歴で相手を選ぶ同類交配が存在していました。一方で、日本人集団では背の高さはあまり影響していませんでした。納豆消費量やヨーグルトの消費量、運動習慣、糖尿病、心血管疾患、など“生活習慣”に関わる項目で同類交配の影響が示唆されていています。先ほどの食事の話ですが、何を食べるのかはゲノムで決まります。さらには疾病リスクにも関わってくる可能性があるのです」
喫煙についても興味深い知見がある。喫煙の経験の有無には環境要因の影響が大きく、遺伝的背景の影響は相対的に小さい。しかし、一度吸い始めるとどれくらいの量を吸うのか、たばこをやめられるかということは遺伝的背景に影響されやすいという。
岡田教授の視線は、さらに古代へと遡る。古代日本人である縄文人と現代日本人集団のゲノム比較により、本州では現代人の10〜20%、与論島(鹿児島県)など南西諸島では最大25%程度に縄文人由来のゲノム配列が保たれていることが判明した。そして、縄文人のゲノムが多く残っている人ほど、肥満傾向があることも明らかになった。
このように、日本人集団の多様性、起源、そして健康に関わる遺伝的背景を明らかにすることは、疾患リスクの理解に貢献するだけでなく、文化や生活習慣のルーツにも迫ることができる。こうした研究成果は、ゲノム情報の理解が個人の健康や嗜好にとどまらず、社会や倫理の問題と結びついている。岡田教授は、遺伝情報の社会実装において、特に「望ましい子ども」を選ぶ技術への懸念を強く抱いている。
「例えば“高身長になる確率が高い”というだけで受精卵を選別するような商業サービスが、すでに海外で始まっています。しかし、予測される数値には大きなばらつきがあり、そこには不確実性がつきまといます」
岡田教授らの研究チームは、実際にBBJのゲノムデータを用い、仮想的な親の組み合わせから次世代のゲノムをシミュレートし、得られる予測値にどの程度のばらつきがあるかを分析した。その結果、同じ両親から得られる複数の胚のうち、最も背が高くなると予測された胚が、実際には最も低くなる可能性もあることが示された。
「シミュレーションにこうした“ふらつき”があるのは科学的に当然のことです。でもその不確実性の意味が社会に正しく伝わっておらず、利用者はともすると予測結果が絶対的に正しいものだと信じ込んでしまう。研究成果を単に論文として発表するだけではなく、それがどういう意味を持つのかを社会に適切に伝える責任が、我々研究者にはあると思っています」
こうした課題意識は、岡田教授の研究姿勢の根幹にもつながっている。医師としての臨床経験を経て、統計学・進化学・情報科学など複数の分野を横断する研究を行ってきた岡田教授にとって、科学の本質とは「自由」であり「好奇心」だという。
「僕は“Curiosity-driven”、つまり好奇心に動かされるタイプの研究者です。理由はよく分からないけど自分の中から不思議と湧き上がってくる疑問や興味を大事にしてきました。医学部時代は社会医学や保健医学に興味を持っていましたし、その後の遺伝統計学についても好きなことを自分のペースで続けること、それが一番大事ですね」
その姿勢は、研究成果の還元にも表れている。遺伝統計学という新しい分野の普及のために、自ら主催してきた「遺伝統計学・夏の学校」という公開講座には、高校生から大学の名誉教授まで多様な人々が集まる。専門用語を嚙み砕き、難解な数理モデルを日常の例に置き換えて語る岡田教授の講義は、「分かりやすいのに奥が深い」と毎年好評を博している。
「私は臨床の医師にはなれませんでしたが、やはり医学研究を行っているので、何かしら、患者さんに還元できるような研究を世に出していきたいと思っています」
ゲノム研究の成果は、今まさに医療応用に直結しつつある。中でも注目されているのが「ポリジェニック・リスク・スコア(PRS)」と呼ばれる指標だ。これは数百から数千の遺伝子変異の効果を統合し、疾患の発症リスクを数値化する手法である(図2)。
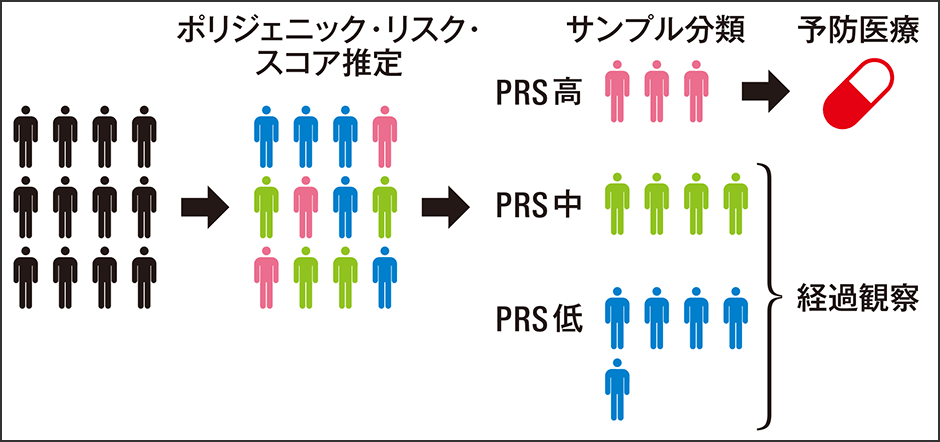
図2 ポリジェニック・リスク・スコアとゲノム個別化医療ポリジェニック・リスク・スコアを推定することによって、加齢などにより一定の割合で発症する疾患において、あらかじめ発症リスクの高いサンプルを同定して予防医療を行うことができる。
「糖尿病などにおけるリスク予測精度はかなり高まっています。特に痩せ型の糖尿病患者では、遺伝的影響が強く、PRSによる予測精度も高いことが分かりました」
一方で、肥満型の糖尿病では、環境因子の寄与が大きく、ゲノム情報だけでは予測が難しい。さらに、欧米人集団と日本人集団とで疾患関連遺伝子の構成が異なるため、「人種集団間の互換性の低さ」も課題とされる。
「同じPRSでも、どの集団で作られたかによって予測精度が変わってしまう。国や地域ごとのゲノムリソース構築が、ますます重要になってきます」
「予測はかなりの精度でできるようになっています。そのリスクをどう個人に伝え、そしてどう行動変容に結びつけるのか。そこには研究者の大きな責任があります」
ゲノム科学の進展は、単なる「予測の精度」ではなく、「どう生きるか」「どう理解し合うか」という問いへとつながっている。岡田教授の研究は、科学と社会の接点でこそ真価を発揮する。多くが解明されているように思えるゲノム情報だが、実はまだ氷山の一角でしかなく、ほとんどが未解明だという。
「いろんなアプローチから研究を進めてきましたが、やっぱり人間ってなんでこんなに違うのだろうという最初の問いに戻ってくるんですよね。その問いに対して、ゲノムは一つの手がかりを与えてくれるものだと思います」